JOIN 심화 학습
5주차 고급 SQL 활용
데이터 웨어하우스와 SQL 기본에 대해 배우고 이를 바탕으로 데이터 분석에 대해 학습 (4)
학습 주제: JOIN
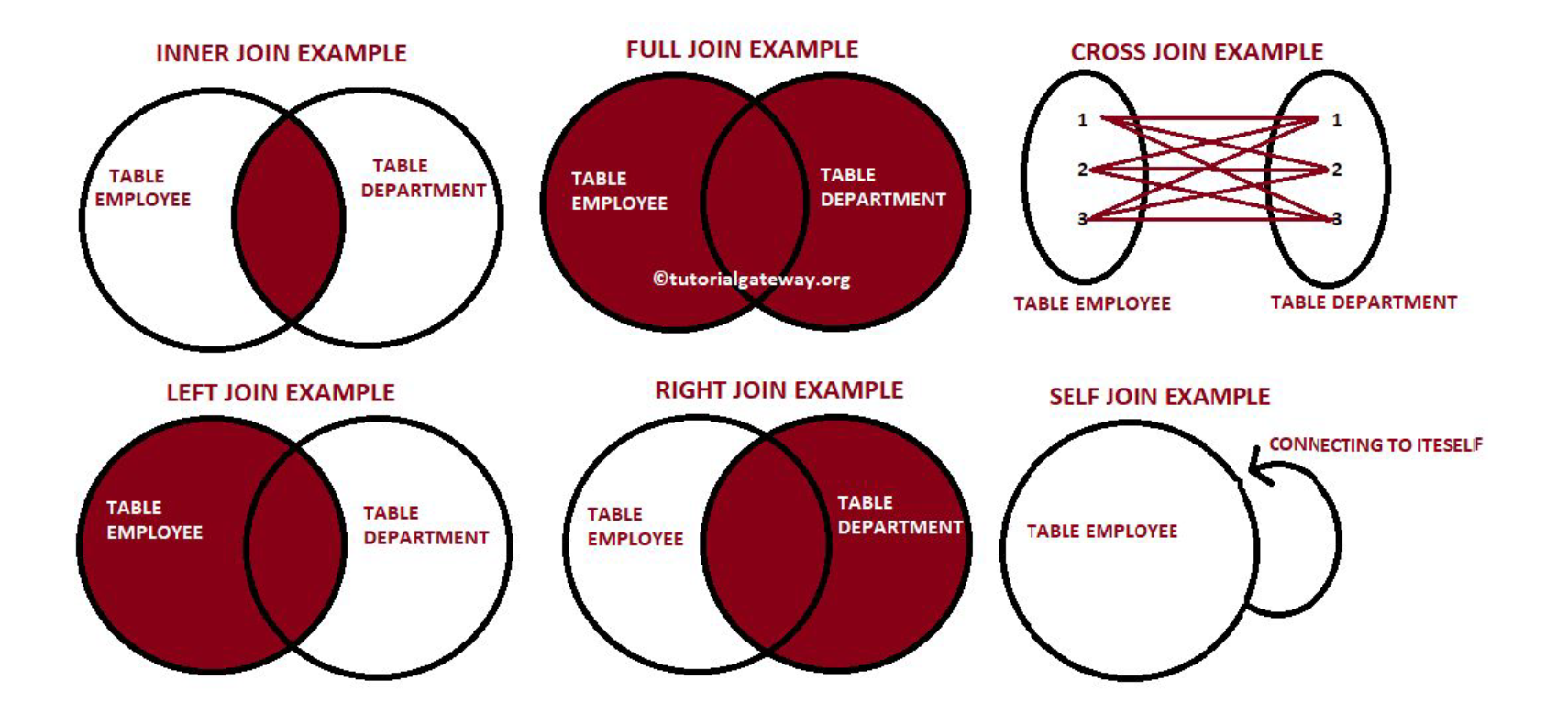
각 JOIN에 대해 설명하기 전에, JOIN 문법 자체의 기본 틀을 설명하자면 다음과 같다.

JOIN 시에는 먼저 중복 레코드가 없고, Primary Key의 uniqueness가 보장됨을 체크해야 한다.
또한 조인하는 테이블들 간의 관계를 명확하게 정의해야 한다.(One to one, One to many, Many to Many)
Many to many 같은 경우에는 가능하다면 one to one이나 one to many로 변환하여 조인하는 것이 덜 위험하다고 한다.
어느 테이블을 베이스로 잡을지, 즉 From에 사용할지 결정하는 것도 중요하다.

위와 같은 테이블이 있다고 하고 각 JOIN의 결과를 직접 보면서 이해해보기로 한다.
1. INNER JOIN
양쪽 테이블에서 매치가 되는 레코드들만 리턴.
양쪽 테이블의 필드가 모두 채워진 상태로 리턴됨.
SELECT * FROM raw_data.Vital v
JOIN raw_data.Alert a ON v.VitalID = a.VitalID;

2. LEFT JOIN
왼쪽 테이블(Base)의 모든 레코드들을 리턴.
오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴
SELECT * FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;

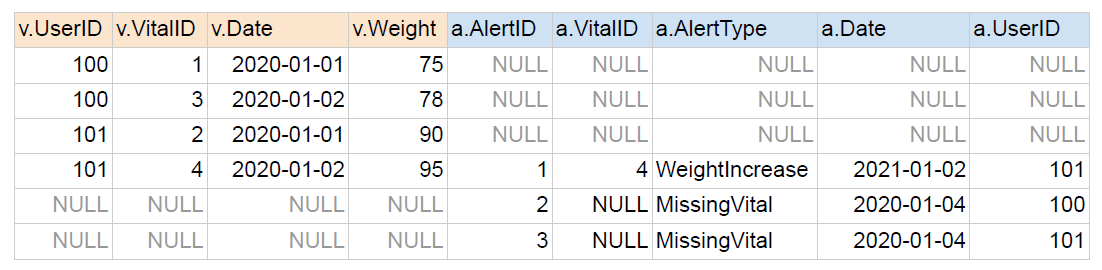
3. FULL JOIN
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴.
매칭되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 리턴
SELECT * FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;
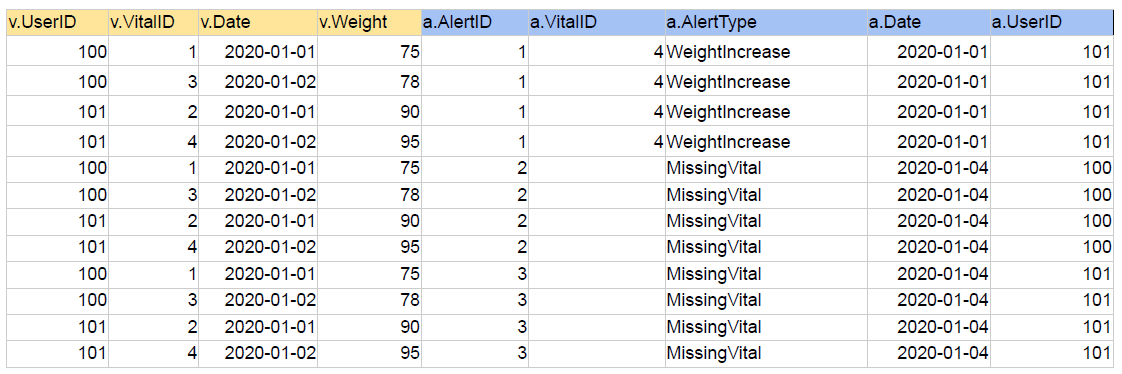
4. CROSS JOIN
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴
SELECT * FROM raw_data.Vital v CROSS JOIN raw_data.Alert a;
5. SELF JOIN
동일한 테이블을 alias를 달리해서 자기 자신과 조인
SELECT * FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = vitalID;

복잡한 JOIN 시 먼저 JOIN 전략을 수립해야 한다.
모든 데이터 분석이 그렇지만 데이터 전처리 단계에서 노가다(!)를 좀 뛰어야 전략을 제대로 세울 수 있다.
공부하며 어려웠던 내용
CROSS JOIN, SELF JOIN 쓸 일이 별로 없어서 사례나 예제를 좀 찾아보고 싶다.

그냥 심심해서 챗지피티한테 물어봤는데 CROSS JOIN은 말그대로 조합을 많이 생성하고 싶을 때 쓰는 것 같고, SELF JOIN은 더 설명해달라고 요청했다.
SELF JOIN은 한 테이블 내의 레코드들 사이의 관계를 쿼리하기 위해 사용되며, 특히 계층적 데이터나 반복적 관계를 다룰 때 유용합니다.
이렇게 말하니까 이해가 좀 되는 것 같았다. 계층적 데이터!
다음은 챗지피티가 들어준 예시들이다.


한 테이블 내에서 서로 참조하거나 계층적 카테고리 구조가 있을 때 확실히 필요할 것 같다.
궁금증 해결!
SQL 가지고 프로젝트까지 했는데도 아직 갈 길이 먼 것 같다. 파이썬처럼 손에 익을 때까지 연습 열심히 해야지